Teknik
Motor
Samhälle
Spel
Popkultur
Fritid
Tjock
Tester
Dagens fråga
 Tipsa!
Skaffa Feber+
Wikipedia släpper dataset för AI-träning
I förhoppning att slippa AI-bottar på sin tjänst
Tipsa!
Skaffa Feber+
Wikipedia släpper dataset för AI-träning
I förhoppning att slippa AI-bottar på sin tjänst
 Foto: Oberon Copeland / Wikipedia
Wikipedia har nu tagit fram ett dataset som man hoppas AI-företag kommer att använda för att träna upp sina AI-modeller istället för att företagens AI-bottar ska spindla runt på uppslagsverkets webbplats. Bottar som spindlar runt på nätet för att hitta ny data för att träna upp AI-modeller har blivit lite av ett problem för både Wikipedia och andra sajter. Tidigare i år uppgav Wikipedia till exempel att bandbredden som går åt till att driva deras tjänst ökat med 50 procent mellan januari och april, något som uppges bero på den stora mängden AI-bottar som spindlar runt på tjänsten.Wikipedias dataset släpps tillsammans med tjänsten Kaggle. Det kommer initialt att innehålla data från Wikipedia på engelska och franska. Datasetet går att ladda ner från Kaggle på länken nedan.
enterprise.wikimedia.com
Internet,
Tjänster,
wikipedia,
ai-bottar,
ai-träning,
ai-modeller,
artificiell intelligens,
kaggle
Via
kaggle.com
Cloudflare fångar bottar som inte sköter sig
Blir fast i en AI-labyrint
Foto: Oberon Copeland / Wikipedia
Wikipedia har nu tagit fram ett dataset som man hoppas AI-företag kommer att använda för att träna upp sina AI-modeller istället för att företagens AI-bottar ska spindla runt på uppslagsverkets webbplats. Bottar som spindlar runt på nätet för att hitta ny data för att träna upp AI-modeller har blivit lite av ett problem för både Wikipedia och andra sajter. Tidigare i år uppgav Wikipedia till exempel att bandbredden som går åt till att driva deras tjänst ökat med 50 procent mellan januari och april, något som uppges bero på den stora mängden AI-bottar som spindlar runt på tjänsten.Wikipedias dataset släpps tillsammans med tjänsten Kaggle. Det kommer initialt att innehålla data från Wikipedia på engelska och franska. Datasetet går att ladda ner från Kaggle på länken nedan.
enterprise.wikimedia.com
Internet,
Tjänster,
wikipedia,
ai-bottar,
ai-träning,
ai-modeller,
artificiell intelligens,
kaggle
Via
kaggle.com
Cloudflare fångar bottar som inte sköter sig
Blir fast i en AI-labyrint
 58.5°
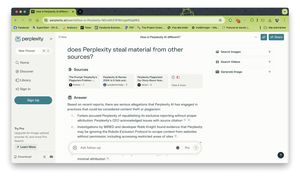
AI-tjänsten Perplexity stjäl hej vilt från medier
Struntar helt i grundläggande riktlinjer på nätet
58.5°
AI-tjänsten Perplexity stjäl hej vilt från medier
Struntar helt i grundläggande riktlinjer på nätet
 28.9°
41.4°
28.9°
41.4°
 Wille Wilhelmsson
Wille Wilhelmsson
tis. 22 apr 2025, 12:00
+
Per månad
39 kr
Betala löpande per månad. Ingen bindningstid.
Starta prenumeration
Per år
299 kr
Enklast och billigast, bara 25 kronor i månaden. Betala löpande per år. Ingen bindningstid.
Prova 14 dagar gratis innan du bestämmer dig.
Starta gratis provperiod
Engångsköp
349 kr
Slipp återkommande betalningar, betala ett år i taget. Betala med kort eller Swish.
Köp utan prenumeration